
Để có thể thực sử hiểu được cách phân nhánh của Git, chúng ta cần nhìn và xem xét lại cách Git lưu trữ dữ liệu. Như bạn đã biết từ Chương 1, Git không lưu trữ dữ liệu dưới dạng một chuỗi các thay đổi hoặc delta, mà thay vào đó là một chuỗi các ảnh (snapshot).
Khi bạn commit, Git lưu trữ đối tượng commit mà có chứa một con trỏ tới ảnh của nội dung bạn đã tổ chức (stage), tác giả và thông điệp, hay 0 hoặc nhiều con trỏ khác trỏ tới một hoặc nhiều commit cha trực tiếp của commit đó: commit đầu tiên không có cha, commit bình thường có một cha, và nhiều cha cho commit là kết quả được tích hợp lại từ hai hoặc nhiều nhánh.
Nhánh Là Gì?
Để hình dung ra vấn đề này, hãy giả sử bạn có một thư mục chứa ba tập tin, và bạn tổ chức tất cả chúng để commit. Quá trình tổ chức các tập tin sẽ thực hiện băm từng tập (sử dụng mã SHA-1 được đề cập ở Chương 1), lưu trữ phiên bản đó của tập tin trong kho chứa Git (Git xem chúng như là các blob), và thêm mã băm đó vào khu vực tổ chức:
$ git add README test.rb LICENSE
$ git commit -m 'initial commit of my project'Lệnh git commit khi chạy sẽ băm tất cả các thư mục trong dự án và lưu chúng lại dưới dạng đối tượng tree. Sau đó Git tạo một đối tượng commit có chứa các thông tin mô tả (metadata) và một con trỏ trỏ tới đối tương tree gốc của dự án vì thế nó có thể tạo lại ảnh đó khi cần thiết.
Kho chứa Git của bạn bây giờ có chứa năm đối tượng: một blob cho nội dung của từng tập tin, một "cây" liệt kê nội dung của thư mục và chỉ rõ tên tập tin nào được lưu trữ trong blob nào, và một commit có con trỏ trỏ tới cây gốc và tất cả các thông tin mô tả commit. Về mặt lý thuyết, dữ liệu trong kho chứa Git có hình dạng như trong Hình 3-1.
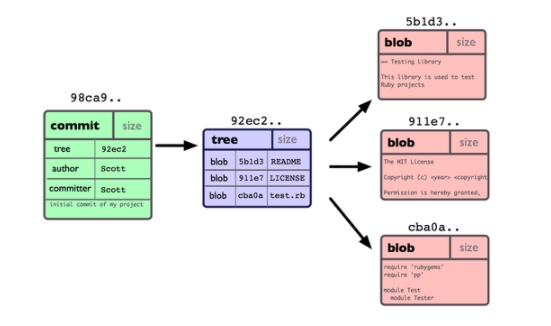 Hình 3-1. Dữ liệu trong kho chứa với một commit.
Hình 3-1. Dữ liệu trong kho chứa với một commit. Nếu bạn thực hiện một số thay đổi và commit lại thì commit tiếp theo sẽ lưu một con trỏ tới commit ngay trước nó. Sau hai commit, lịch sử của dự án sẽ tương tự như trong Hình 3-2.
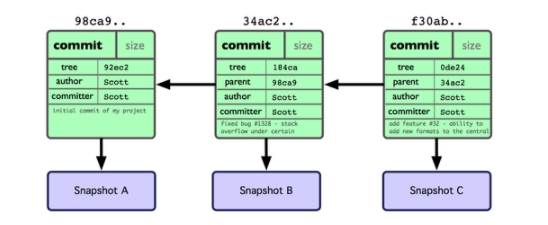 Hình 3-2. Các đối tượng dữ liệu của Git trong kho chứa nhiều commit.
Hình 3-2. Các đối tượng dữ liệu của Git trong kho chứa nhiều commit. Một nhánh trong Git đơn thuần là một con trỏ có khả năng di chuyển được, trỏ đến một trong những commit này. Tên nhánh mặc định của Git là master. Như trong những lần commit đầu tiên, chúng đều được trỏ tới nhánh master. Và mỗi lần bạn thực hiện commit, nó sẽ được tự động ghi vào theo hướng tiến lên. (move forward)

Chuyện gì xảy ra nếu bạn tạo một nhánh mới? Làm như vậy sẽ tạo ra một con trỏ mới cho phép bạn di chuyển vòng quanh. Ví dụ bạn tạo một nhánh mới có tên testing. Việc này được thực hiện bằng lệnh git branch:
$ git branch testing
Nó sẽ tạo một con trỏ mới, cùng trỏ tới commit hiện tại (mới nhất) của bạn (xem Hình 3-4).

Vậy làm sao Git có thể biết được rằng bạn đang làm việc trên nhánh nào? Git giữ một con trỏ đặc biệt có tên HEAD. Lưu ý khái niệm về HEAD ở đây khác biệt hoàn toàn với các VCS khác mà bạn có thể đã sử dụng qua, như là Subversion hoặc CVS. Trong Git, đây là một con trỏ tới nhánh nội bộ mà bạn đang làm việc. Trong trường hợp này, bạn vẫn đang trên nhánh master. Lệnh git branch chỉ tạo một nhánh mới chứ không tự chuyển sang nhánh đó cho bạn (xem Hình 3-5).

Để chuyển sang một nhánh đang tồn tại, bạn sử dụng lệnh git checkout. Hãy cùng chuyển sang nhánh testing mới:
$ git checkout testing
Lệnh này sẽ chuyển con trỏ HEAD sang nhánh testing (xem Hình 3-6).
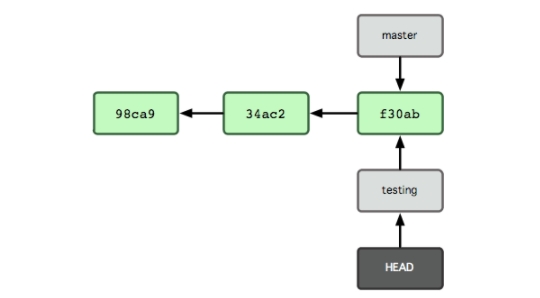 Hình 3-6. HEAD trỏ tới nhánh khác khi bạn chuyển nhánh.
Hình 3-6. HEAD trỏ tới nhánh khác khi bạn chuyển nhánh.
Ý nghĩa của việc này là gì? Hãy cùng thực hiện một commit khác:
$ vim test.rb
$ git commit -a -m 'made a change'
Điều này thật thú vị, bởi vì nhánh testing của bạn bây giờ đã tiển hẳn lên phía trước, nhưng nhánh master thì vẫn trỏ tới commit ở thời điểm khi bạn chạy lệnh git checkout để chuyển nhánh. Hãy cùng chuyển trở lại nhánh master:
$ git checkout master
Hình 3-8 hiển thị kết quả.
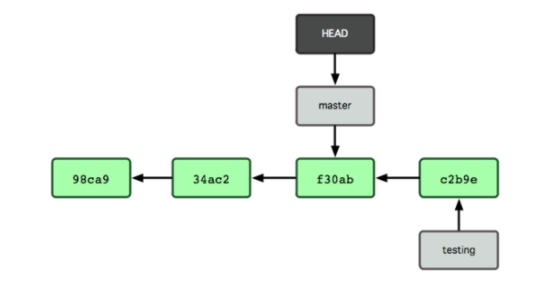 Hình 3-8. HEAD chuyển sang nhánh khác khi checkout.
Hình 3-8. HEAD chuyển sang nhánh khác khi checkout. Lệnh này vừa thực hiện hai việc. Nó di chuyển lại con trỏ về nhánh master, và sau đó nó phục hồi lại các tập tin trong thư mục làm việc của bạn trở lại snapshot mà master trỏ tới. Điều này cũng có nghĩa là các thay đổi bạn thực hiện từ thời điểm này trở đi sẽ tách ra so với phiên bản cũ hơn của dự án. Nó "tua lại" các thay đổi cần thiết mà bạn đã thực hiện trên nhánh testing một cách tạm thời để bạn có thể đi theo một hướng khác.
Hãy cùng tạo một vài thay đổi và commit lại một lần nữa:
$ vim test.rb
$ git commit -a -m 'made other changes'Bây giờ lịch sử của dự án đã bị tách ra (xem Hình 3-9). Bạn tạo mới và chuyển sang một nhánh, thực hiện một số thay đổi trên đó, và rồi chuyển ngược lại nhánh chính và tạo thêm các thay đổi khác. Cả hai sự thay đổi này bị cô lập với nhau ở hai nhánh riêng biệt: bạn có thể chuyển đi hoặc lại giữa cách nhánh và tích hợp chúng lại với nhau khi cần thiết. Và bạn đã thực hiện những việc trên một cách đơn giản với lệnh branch và checkout.
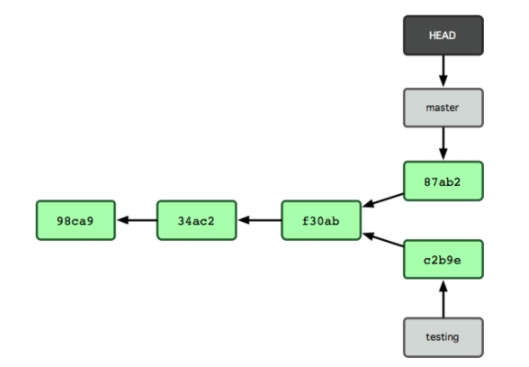 Hình 3-9. Lịch sử các nhánh đã bị phân tách.
Hình 3-9. Lịch sử các nhánh đã bị phân tách.
Bởi vì một nhánh trong Git thực tế là một tập tin đơn giản chứa một mã băm SHA-1 có độ dài 40 ký tự của commit mà nó trỏ tới, chính vì thế tạo mới cũng như hủy các nhánh đi rất đơn giản. Tạo mới một nhánh nhanh tương đương với việc ghi 41 bytes vào một tập tin (40 ký tự cộng thêm một dòng mới).
Điều này đối lập rất lớn với cách mà các VCS khác phân nhánh, chính là copy toàn bộ các tập tin hiện có của dự án sang một thư mục thứ hai. Việc này có thể mất khoảng vài giây, thậm chí vài phút, phụ thuộc vào dung lượng của dự án, trong khi đó trong Git thì quá trình này luôn xảy ra ngay lập tức. Thêm một lý do nữa là, chúng ta đang lưu trữ cha của các commit, nên việc tìm kiếm gốc/cơ sở để tích hợp lại được thực hiện một cách tự động và rất dễ dàng. Những tính năng này giúp khuyến khích các lập trình viên tạo và sử dụng nhánh thường xuyên hơn.

Thảo luận về Bài viết